The first time I looked at DynamoDB, it felt like a golden unicorn. It promised fast access, huge scale, and very little operational effort. If you’re already building on AWS, it also feels like the natural choice because it fits so neatly into the rest of the platform.
Then the catch becomes clear. DynamoDB isn’t magical because it answers every possible query quickly. It’s magical because it can answer the queries you planned for very quickly.
If you come from PostgreSQL, MySQL, or even MongoDB, DynamoDB can feel less flexible than you expected at first. Once you understand that trade-off, it becomes much easier to see where DynamoDB shines and where another database is the better fit.
Why DynamoDB Looks So Good in AWS
There’s a lot to like.
- It’s fully managed, so there’s no server patching, vacuuming, or cluster babysitting.
- It’s built for very high throughput and low-latency lookups.
- It scales horizontally without you having to plan sharding yourself.
- It integrates nicely with AWS features such as Lambda, IAM, Streams, TTL, and Global Tables.
- It works especially well for event-driven and serverless architectures where you want the database to disappear into the background.
That’s a powerful set of selling points. If your application mostly does key-based lookups, time-ordered queries within a partition, and predictable access patterns, DynamoDB can feel wonderful. It removes a lot of the infrastructure and scaling concerns that teams otherwise spend time worrying about.
This is why DynamoDB turns up so often in AWS architecture diagrams. Within AWS, it’s one of the cleanest ways to build something that needs to stay fast as traffic grows.
So What Are You Buying Into?
The important thing to understand is that DynamoDB isn’t giving you arbitrary query speed. It’s giving you excellent performance for access patterns you designed for up front.
That means the real design work moves earlier in the project. With PostgreSQL or MySQL, you can often start with a sensible schema, add a few indexes, and answer new questions later with SQL joins, filters, and aggregations. With DynamoDB, your partition key, sort key, and secondary indexes have a much bigger influence on what’s easy, what’s awkward, and what’s expensive.
That’s the trade-off. You get scale and speed, but you pay for them in data modelling discipline. If a new query arrives later and you didn’t design an index or item layout that supports it, you can end up in a tight spot. Sometimes that means adding a new global secondary index (GSI). Sometimes it means backfilling data. Sometimes it means accepting a less elegant design than you’d have liked.
I think this is the best way to frame DynamoDB:
DynamoDB isn’t hard because it’s bad at queries. It’s hard because it asks you to commit to your important queries much earlier than relational databases do.
A Small Toy Example
Imagine a generic application with three kinds of data:
- accounts
- items
- activity events
Now imagine the application needs to answer these questions:
- Fetch one account by ID.
- Fetch one item by ID.
- List the 20 most recent events for an account.
- List all items owned by an account.
- List all items for an account with a given status.
- Show the most recent events for one item.
That set of queries already hints at the difference between the database styles.
In PostgreSQL or MySQL, you’d probably model accounts, items, and events as separate tables.
You’d add foreign keys, then create indexes to support common filters such as account_id, item_id, status, and created_at.
If you later need a new query, you often have room to add another index or write a new join without changing how the data is fundamentally stored.
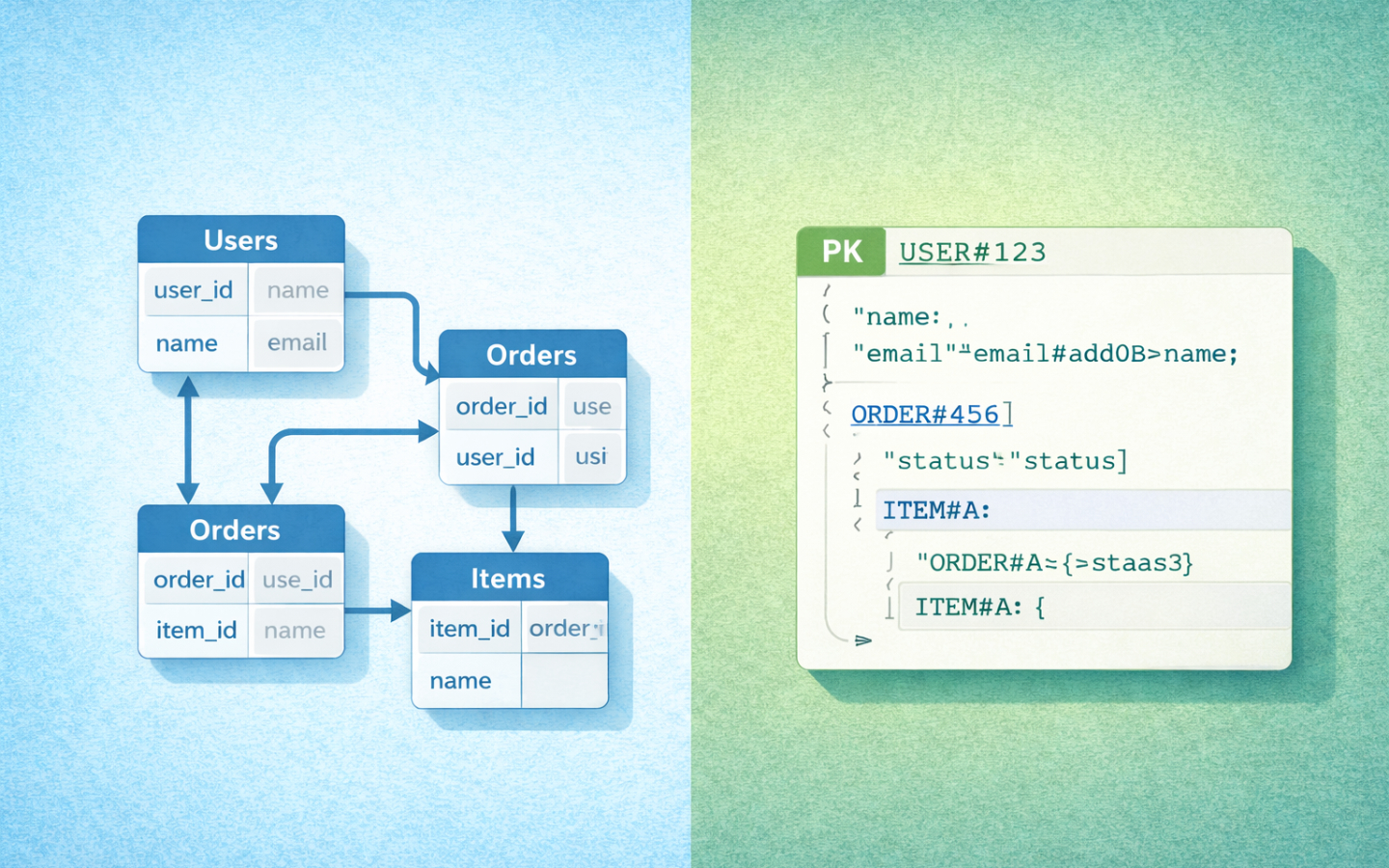
In DynamoDB, you start by asking how each of those reads will work. You might decide that the main partition key should group everything by account, so an account and all of its related records can be read efficiently together. You might use sort key prefixes so that account metadata, owned items, and recent events all sit in one item collection in a predictable order. If you also need to fetch an item directly by ID, you may add a secondary index for that access pattern.
That’s where single-table design often enters the conversation. Instead of having separate tables for accounts, items, and events, you can keep multiple entity types in one table and distinguish them with key prefixes and attributes. For people coming from SQL, this can look odd at first. For DynamoDB, it’s often the most natural way to serve related access patterns efficiently.
The upside is speed. The downside is that the model is built around the questions you know today. If someone later asks for “all items with status open across every account, sorted by last update”, that query may be trivial in PostgreSQL with the right index and much more awkward in DynamoDB if you didn’t already design for it.
That’s the key mindset shift. Relational databases let you ask more questions later. DynamoDB rewards you for knowing your important questions earlier.
DynamoDB Versus PostgreSQL and MySQL
For many readers, this is the most useful comparison because PostgreSQL and MySQL are the baseline databases people already know. In AWS terms, that often means comparing DynamoDB with Amazon RDS or Aurora running one of those engines.
The relational options are usually better when:
- the relationships between entities matter
- you need joins regularly
- query patterns are still evolving
- reporting and ad hoc filtering matter
- the team wants a familiar SQL workflow
- transactional consistency across multiple records is central to the design
DynamoDB is usually better when:
- request patterns are known and stable
- low-latency lookups matter more than query flexibility
- the workload needs to scale very aggressively
- the application is already built around AWS-native services
- you want as little operational database work as possible
This is why I wouldn’t frame DynamoDB as a replacement for PostgreSQL or MySQL in every AWS system. It’s a specialist tool. It’s extremely good at a particular style of workload.
PostgreSQL and MySQL are more forgiving. They let you discover new questions over time. DynamoDB is less forgiving, but can be outstanding when your access paths are clear and the read and write patterns fit its model.
It’s also worth saying that needing a little schema flexibility doesn’t automatically push you into DynamoDB. PostgreSQL and MySQL both support JSON data types, so “some of this data doesn’t fit neatly into columns” is not, on its own, a strong reason to leave the relational world behind.
One subtle trade-off is that secondary indexes aren’t free. They make more queries possible, but they also add more design complexity and more write overhead. Even read consistency has caveats. Strongly consistent reads are available on tables and local secondary indexes, but not on global secondary indexes. That’s the kind of detail that rarely matters in a relational database comparison until you’re well into implementation.
Where MongoDB and Cosmos DB Fit
MongoDB and Cosmos DB sit closer to DynamoDB in spirit because they’re both happy to move away from a classic relational model. Even so, they don’t feel the same in practice.
MongoDB usually feels more flexible than DynamoDB. You store JSON-like documents, the document model is easy to understand, and adding new query patterns often feels more natural than it does in DynamoDB. If your team wants a document database but doesn’t want to think quite so aggressively in terms of partition keys and access-pattern-first modelling, MongoDB can feel more comfortable. It also supports transactions, but the main design story is still about modelling documents well rather than assuming transactions remove all schema trade-offs.
The trade-off is that MongoDB doesn’t give you the same AWS-native experience as DynamoDB. It’s also not the same thing operationally or architecturally. DynamoDB is more opinionated, but that opinionation is part of how AWS delivers its scaling and operational simplicity.
Cosmos DB is probably the closest cloud-provider analogue to DynamoDB. If DynamoDB is the AWS-flavoured answer to globally distributed NoSQL, Cosmos DB is the Azure-flavoured one. Both care deeply about partitioning. Both reward good access-pattern design. Both are strongest when you embrace their distributed nature instead of pretending they’re just drop-in replacements for a relational database.
The differences are still worth noting. Cosmos DB exposes multiple APIs, has explicit consistency-level choices, and scopes ACID transactions to a single logical partition in its transactional batch model. DynamoDB has its own shape of trade-offs around partition keys, GSIs, and consistency, but inside AWS it tends to feel more native and more obvious as the default managed NoSQL option.
If you’re building mainly on AWS, DynamoDB is usually the more natural choice. If you’re building mainly on Azure, Cosmos DB often occupies the same part of the design conversation.
The Unique Selling Points of DynamoDB
If I were making the positive case for DynamoDB, these are the points I’d lead with.
- It removes a huge amount of operational effort.
- It scales very well when the partitioning is sound.
- It encourages you to design around real application access patterns instead of drifting into accidental database complexity.
- It fits beautifully with event-driven AWS systems.
- It can deliver extremely fast, predictable reads for the patterns it’s built to support.
Those are real advantages. They’re not marketing fluff. Used well, DynamoDB genuinely can simplify a system while keeping it fast under load.
Another place DynamoDB often feels especially natural is for system-managed data rather than user-driven data. If the application controls the shape of the records and already knows the main read and write patterns, DynamoDB becomes much easier to model well. A cache of serialized application objects keyed by a hash is a good example. The access pattern is simple, the data shape is predictable, and features like TTL fit neatly.
That doesn’t mean DynamoDB is only for internal plumbing. It just means it tends to feel easiest when the system owns the questions as well as the data.
The Trade-Offs You Accept
To get those advantages, you accept some real constraints.
- Data modelling becomes more specialised.
- Partition key choice becomes a first-class architectural decision.
- New queries can be painful if you didn’t think ahead.
- Joins aren’t part of the story.
- Secondary indexes help, but each one adds cost and design weight.
- Some patterns that feel easy in SQL feel unnatural in DynamoDB.
None of that makes DynamoDB bad. It just means it’s not a golden unicorn after all. It’s a powerful tool with a price of admission.
The teams that struggle with DynamoDB are often the ones trying to use it like a relational database with different syntax. The teams that do well with it are usually the ones who embrace its strengths and avoid asking it to be something it isn’t.
When I Would Choose DynamoDB
I’d seriously consider DynamoDB when all of the following are mostly true:
- the system is already strongly AWS-centric
- the important queries are well understood
- the workload is high-scale or likely to become high-scale
- most reads are key-based or partition-based rather than exploratory
- low operational overhead matters
- the team is willing to invest in modelling the data properly
That’s a very common shape for serverless back ends, event-driven systems, request-tracking platforms, session stores, metadata stores, and similar architectures.
When I Would Reach for Something Else
I’d lean toward PostgreSQL, MySQL, or another more flexible option when:
- the query patterns are still changing often
- the data relationships are rich and important
- the application needs joins, reporting, or analytics-style queries
- the team wants the database to be forgiving while the product evolves
- modelling everything around access patterns feels like premature constraint
In those situations, DynamoDB can still work, but it may not be the database that makes your life easiest.
Wrapping Up
DynamoDB feels magical at first because, in the right circumstances, it really is impressive. It’s fast, scalable, and deeply at home inside AWS.
The important thing is to understand what you’re buying. You’re not buying universal query flexibility. You’re buying excellent performance for the access patterns you planned for, plus a very low-operations experience around them.
That’s a trade many AWS systems should make. It’s just not a trade every system should make.
If you go in with that mindset, DynamoDB stops looking like a golden unicorn and starts looking like something better. It looks like a very good engineering choice for the right kind of problem.